
Paper link | Code link | ICML 2023
這項研究採用了人機互動的解釋方法來處理多模態 Transformers 模型。
視覺-語言模型 (VLM) 很少與使用者對特定答案的推理相吻合。
為了改善這種對齊並強化常識性推理,這項研究提出了一種基於人機互動的調整模式,使用由機器生成的數據進行調整。
InstructGPT 展示了使用人類在迴路中的調整語言模型可以產生比傳統訓練的較大模型更受人類偏好的輸出。
類似地,他們使用人類評論者對自生成樣本的少量互動反饋來指導微調過程。
此外,他們將這種方法應用於多模態應用,促進了語言模型 (LM) 和視覺-語言模型 (VLM) 之間能力的轉移。
他們將任務定義為開放式文本生成。
VQA 元組 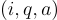 包含圖像 $i$ 和一對對應的文本序列,分別表示問題
包含圖像 $i$ 和一對對應的文本序列,分別表示問題 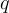 和答案
和答案 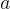 。
。
這項研究使用模型來執行函數 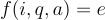 ,其中輸出
,其中輸出  是文本解釋。
是文本解釋。
他們的方法通過自我對話的方式建立一個自然語言常識推理的基線來進行評估。
接著,選擇合適的語言模型候選者。
澄清和上下文資訊都被提示給模型,以預測最終答案。

在每次迭代中,他們使用前一輪調整過的模型,從訓練數據中抽取解釋。
人類通過標記合適的解釋,向模型提供最小的反饋。
抽樣
這種方法結合了 top-k 和溫度抽樣。
首先,他們使用 top-k 抽樣來將生成的序列限制在最有可能的 token 內。
為了過濾 token,他們應用溫度抽樣
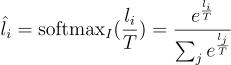
其中 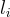 是輸出機率
是輸出機率 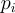 所對應的 token
所對應的 token  的 logit。
的 logit。
人類反饋
他們識別並強化那些符合人類意圖的生成內容。
可以通過使用任務特定的評量標準,將生成的候選解釋與現有的由人類生成的真實解釋進行比較來模擬人類反饋。
在他們的方法中,使用 ROUGE-L 分數進行評估。
持續學習
他們同時訓練 VQA 和解釋生成任務,其訓練損失為
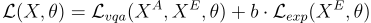
其中 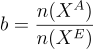 是用來平衡樣本數不均衡的參數,
是用來平衡樣本數不均衡的參數,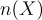 代表集合
代表集合 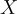 中的元素數量。
中的元素數量。
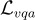 和
和 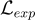 分別是針對答案和解釋的下一個 token 預測的 loss。
分別是針對答案和解釋的下一個 token 預測的 loss。
這項研究考慮了三種視覺語言模型(VLM):
他們使用了六個不同的常識推理基準:
並使用了三個評估指標:BLEU-4、ROUGE-L 和 CIDEr。
下圖顯示了語言模型在自我對話中的表現。

下圖展示了在 VQA-X 訓練集上生成的解釋。


 iThome鐵人賽
iThome鐵人賽